Every team has the same chart. The one that shows median time-to-first-review climbing every quarter while the team stays the same size and the PR volume keeps going up.
It is not a mystery why. Code review is concentrated work. The senior engineers and tech leads who can review credibly are the same people who are writing the most consequential code, in the most meetings, and on the most escalations. The PRs queue. The authors context-switch. The work-in-progress balloons. By the time the review happens, half the context is stale and the reviewer is reading code they barely have time to read carefully.
This blog is about adding a structured first pass to that pipeline. Not replacing the human reviewer. Adding a layer of evidence-based, requirements-traced, scope-aware analysis that lands in the PR before the human even opens it, so the human can spend their attention on judgment instead of discovery.
Reviewing a pull request is not one task. It is at least four:
Each of those is a separate cognitive load, and each of them requires the reviewer to flip between the PR diff, the linked work item, the test files, the requirements document, and sometimes the original Slack thread that started the work. Most of that flipping is overhead, not insight.
Quick note: This is why senior reviewers sometimes skip steps. The substance review gets the attention. Scope, traceability, and test coverage get a glance. The defects that ship are usually the ones hiding in the steps that got skipped, not the ones in the substance the reviewer focused on.
A code review agent is not a linter and it is not an auto-approver. It is a structured analyst that runs through the same four-step pass a senior reviewer would, but does it on every PR, in the same shape, every time.
A well-defined agent operates on a few hard rules:
That last constraint is the one that separates a useful agent from a noisy one. An agent that confidently asserts conclusions it cannot back up makes more work for the human reviewer, not less.
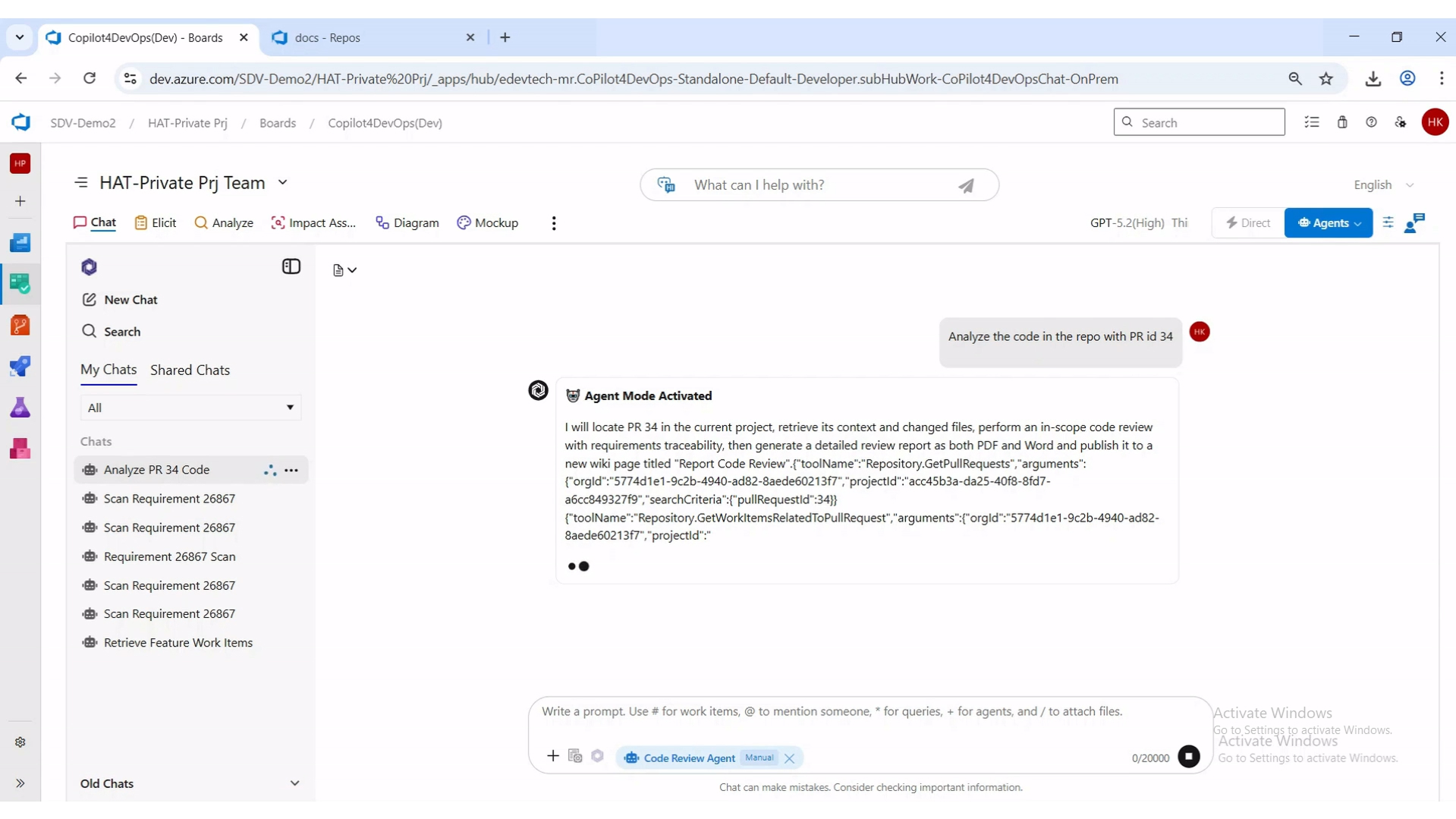
Before any review happens, the agent declares what it is about to do and which tools it will use. The execution plan is visible in chat the moment the run starts.
The agent announces its plan: locate the PR, retrieve context and changed files, perform an in-scope review with requirements traceability, then publish a detailed report. The actual tool calls are visible inline.
This matters for two reasons. First, the team can see exactly what the agent is touching. There is no opaque background process. Second, if the plan is wrong, the human can stop the run and correct the prompt before any analysis happens. Transparency is not a side feature. It is the prerequisite for trust.
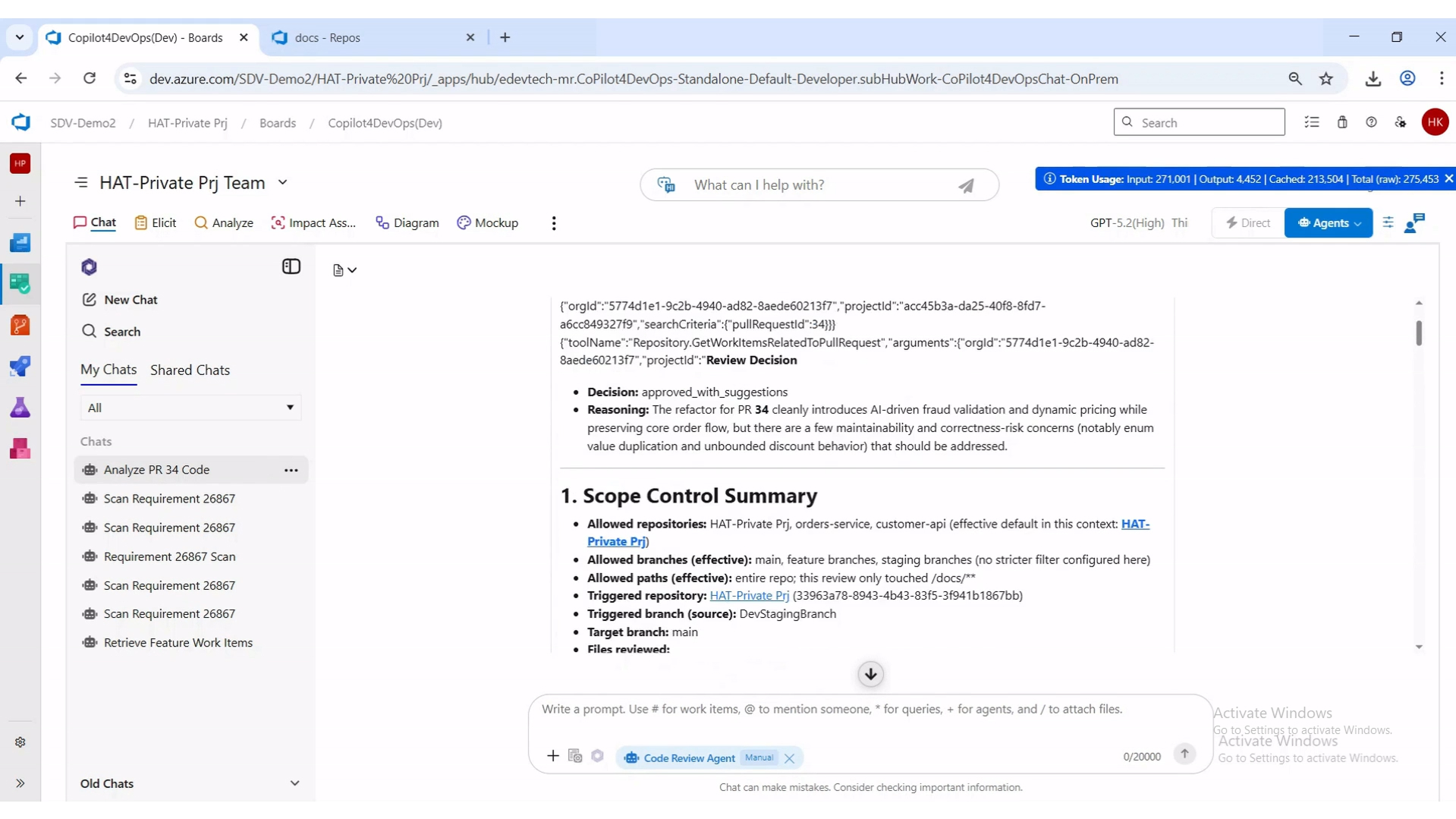
Most review tools hide their conclusion at the bottom. A good agent puts it at the top.
The decision lands first: approved with suggestions, rejected, or needs changes, with a one-paragraph rationale. The Scope Control Summary follows so the reader can immediately see what the agent was permitted to review.
Leading with the decision lets the reader calibrate before they read anything else. If the agent says approved-with-suggestions and the rationale is solid, the human reviewer can scan the rest looking for blockers. If the agent says needs-changes, the human knows to read carefully.
The Scope Control Summary that follows the decision answers the first question every reviewer mentally asks: was this even the right thing to review? Allowed repositories, allowed branches, allowed paths, the triggered repository and branch, and the specific files reviewed are all listed up front. If something feels off, the reader can immediately see whether the agent was even looking at the right code.
Requirements traceability is where most code review tools either over-promise or punt entirely. A useful agent does neither. It walks the trace it can, labels what it cannot, and never invents.
The PR is shown with its linked requirement and task. The traceability section is explicit when full requirement text is unavailable, and labels the resulting traceability as partial.
When the linked requirement and acceptance criteria are fully available in the work item, the agent maps every implementation element back to a specific criterion. When only titles or partial information are available, the agent infers what it can from the context, marks the inferences as inferences, and labels the overall traceability as limited or partial.
That honesty is the feature. A reviewer can act on “traceability_limited because the full AC text is not in the work item.” A reviewer cannot act on a confident-sounding paragraph that is actually built on guesses. The agent that admits its limits is the one whose conclusions you can trust.
The substance of the review is the finding. A useful agent produces findings in a consistent shape, every time, so reviewers can scan a long list quickly.
Every finding includes the same six fields:
Consistent structure means a senior reviewer can scan twenty findings in the time it would take to read three loosely-formatted comments. The reviewer skims severities and categories, drills into the high-severity items, and trusts that the low-severity ones can be batched into a follow-up.
The response closes with two sections that turn the review from a moment into an artifact.
The Final Summary is what gets pasted into the team chat or attached as a PR comment. Scope, requirements/AC satisfaction, top blocking issues, and readiness for human approval all in five short bullets. A reviewer who is short on time can read just this and make a credible decision.
The Generated Report Artifacts section is what protects the team six months later. PDF and Word versions of the full review, plus a wiki page link, give the team a stable, archived record of what the agent saw, what it concluded, and why. When someone asks why a particular PR was approved, the evidence trail exists.
Pro tip: Pin the report wiki page in the work item. The PR will eventually close. The work item will live forever. Linking the audit artifact to the work item rather than the PR keeps it findable.
Not every tool calling itself a code reviewer earns the title. A few properties separate a useful agent from a noisy one.
Teams that adopt this kind of agent stop treating code review as a queue and start treating it as a pipeline. The first pass runs immediately. The second pass, the human one, has the structured first-pass output as input. Time-to-first-review collapses. Quality of attention goes up.